google Colaboratoryで物体検出しました(Keras+tiny-YOLOv3)
google Colaboratory上でKerasを利用し、tiny-YOLOv3で物体検出するまでを実現してみました。ディーブラーニングの知識がなくとも、手順通り実施することで簡単に実現ができました。
今回は1クラスの分類です。自分の娘を検出するというテーマで実施をしました。
データセットの準備
YOLOv3のデータセットは、画像と、アノテーションデータ(検出対象を四角で囲う座標)が必要になります。
一見難しそうですが「labelImage」を使うことで簡単にできます。
ダウンロード先:https://github.com/tzutalin/labelImg
注意:アノテーションのフォーマットをYOLOにしておく必要があります。
作成できると、画像とアノテーション、classesファイルが出来上がります。
僕が実施したときは、classesファイルの中身にデフォルトで関係のないlabelがありましたので、自分が付与したラベルのみにします。
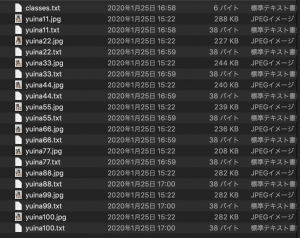
classes.txtの中身
yuina
今回は1つしかないですが、1行目 = クラス番号0となります。
2行目があれば、クラス番号は1となります。
アノテーションデータ(画像名.txtの中身)
0 0.496394 0.512613 0.502404 0.942342
スペース区切りでデータが格納されており、左から順にこのようなデータが格納されています。
- オブジェクト(クラス)番号
- オブジェクトの中心X座標
- オブジェクトの中心Y座標
- オブジェクトの幅
- オブジェクトの高さ
学習の事前準備
ここからはGoogleColaboratoryでの手順になります。
# keras 2.2以上は動作しない(2.1.5以下で動作)
!pip install --user -U keras==2.1.5
# tensorflow 2.0以上は動作しない
!pip install --user -U tensorflow_gpu==1.14.0
#1.14.0にならないときは、一度アンインストールしてから上記コマンドでインストールする。
#!pip uninstall tensorflow tensorflow-tensorboard tensorflow-estimator
# tensorflow 1.14.0であることを確認する# %tensorflow_version 1.x
import tensorflow as tf
tf.__version__
# keras 2.1.5であることを確認する
import keras
keras.__version__
# GPUが使えていることを確認するfrom tensorflow.python.client import device_lib
device_lib.list_local_devices()
KerasでTiny YOLOv3を学習する準備
!git clone https://github.com/Mrlawrance/yolov3-ios
# 学習済み重みをダウンロード
!wget https://pjreddie.com/media/files/yolov3-tiny.weights
mv yolov3-tiny.weights /content/yolov3-ios/yolov3_with_Densenet/
cd /content/yolov3-ios/yolov3_with_Densenet/
#中を確認してみる。
ls
#設定ファイルをclasses=2に変更し作成する
!sed s/classes=80/classes=2/ yolov3-tiny.cfg > yolov3-tiny2.cfg
# tiny学習用にpythonファイルを変更し作成する(anchor_pathをtiny用に変更)
!sed s/yolo_anchors.txt/tiny_yolo_anchors.txt/ yolov3_train.py > yolov3-tiny_train.py
# 学習済重みを.h5ファイルへ変換
!python convert.py -w yolov3-tiny2.cfg yolov3-tiny.weights model_data/tiny_yolo_weights.h5
# model_data/voc_classes.txtを変更(echoにクラス名を書きます)
!echo 'yuina' > model_data/voc_classes.txt
#確認
!cat model_data/voc_classes.txt
データセットの格納
#GoogleDriveをマウント
from google.colab import drive
drive.mount('/content/gdrive')
※ドライブの認証用URLが出力されますので、リンクをクリックし、Googleアカウントの認証を行うことで、マウントが完了します
マウントができましたら、zip圧縮したデータセットをアップロードしておきます。
#アップロードしたデータセットの確認
!ls -l /content/drive/My\ Drive/yolo/yuina_dataset.zip
#データセットを作業用(カレント)にコピー
!cp -p '/content/drive/My Drive/yolo/yuina_dataset.zip' .
#zipファイルの解凍
!unzip yuina_dataset.zip
#中身の確認
!cat yuina_dataset/*.txt
yuina ←classese.txt
0 0.575721 0.524324 0.598558 0.886486 ←画像名1.txt(以下省略)
0 0.496394 0.512613 0.502404 0.942342
0 0.516827 0.526126 0.581731 0.915315
0 0.504808 0.547748 0.615385 0.879279
0 0.536058 0.556757 0.596154 0.875676
0 0.461538 0.522523 0.562500 0.882883
0 0.536058 0.565766 0.471154 0.825225
0 0.576923 0.581982 0.543269 0.760360
0 0.575721 0.524324 0.598558 0.886486
0 0.575721 0.524324 0.598558 0.886486
train.txtの作成
# train.txtの作成
import glob
#画像ファイル名を指定し、画像の縦横のpixel数を設定する
files = glob.glob("yuina_dataset/*.jpg")
#width = height = 416
width = 416
height = 555
with open("train.txt", mode='w') as outf:
for imgfile in files:
body, ext = imgfile.split('.')
out = imgfile
with open(body + ".txt") as f:
lines = f.readlines()
for line in lines:
line = line.strip()
classid, cx, cy, w, h = line.split()
xmin = (float(cx) - float(w)/2)*width
xmax = (float(cx) + float(w)/2)*width
ymin = (float(cy) - float(h)/2)*height
ymax = (float(cy) + float(h)/2)*height
out += ' {},{},{},{},{}'.format(int(xmin), int(ymin), int(xmax), int(ymax), classid)
outf.write(out + '\n')
!head train.txt
こんな中身になっていればOKです。
yuina_dataset/yuina11.jpg 101,23,310,546,0
yuina_dataset/yuina100.jpg 114,44,364,536,0
yuina_dataset/yuina66.jpg 125,85,321,543,0
yuina_dataset/yuina33.jpg 82,60,338,548,0
yuina_dataset/yuina55.jpg 74,45,308,535,0
yuina_dataset/yuina44.jpg 99,66,347,552,0
yuina_dataset/yuina22.jpg 93,38,336,545,0
yuina_dataset/yuina88.jpg 114,44,364,536,0
yuina_dataset/yuina99.jpg 114,44,364,536,0
yuina_dataset/yuina77.jpg 127,112,352,533,0
学習開始!
#オリジナルの学習プログラムをもとに自分の学習プログラムを作成します。
(元プログラムから何回も複製できるように・・・・)
!cp yolov3-tiny_train.py yolov3-tiny_train2.py
# 学習回数の設定(学習150回、ファインチューニング学習50回)
!sed s/epochs=50/epochs=150/ yolov3-tiny_train.py > yolov3-tiny_train.tmp
!sed s/epochs=100/epochs=200/ yolov3-tiny_train.tmp > yolov3-tiny_train.tmp2
!sed s/initial_epoch=50/initial_epoch=150/ yolov3-tiny_train.tmp2 > yolov3-tiny_train2.py
#自分が用意した画像サイズに変換する。
!sed s/416,416/416,555/ yolov3-tiny_train2.py
# 学習(時間がかかると思うので、定期的ブラウザをF5やctl+Rで更新すること)
!python yolov3-tiny_train2.py
#学習が正常終了するとh5ファイルが作成される
ls -l logs/000/trained_weights*.h5
#学習済みモデルファイルをコピー
!cp -p logs/000/trained_weights_final.h5 model_data/yolo.weights
テスト実行(物体検出の実行)
#ディレクトリ移動
cd /content/yolov3-ios/yolov3_with_Densenet/
#あらかじめこの場所(GoogleDrive)に検証対象の画像を入れておく。
!ls yuina/yuina*.jpg
ls model_data/
※こんな感じでファイルがそろっている
coco_classes.txt
tiny_yolo_anchors.txt
voc_classes.txt*
yolo.weights
dense121_weights.h5
tiny_yolo_weights.h5
yolo_anchors.txt
yolo.weights.h5
!cp -p model_data/yolo.weights model_data/yolo.weights.h5
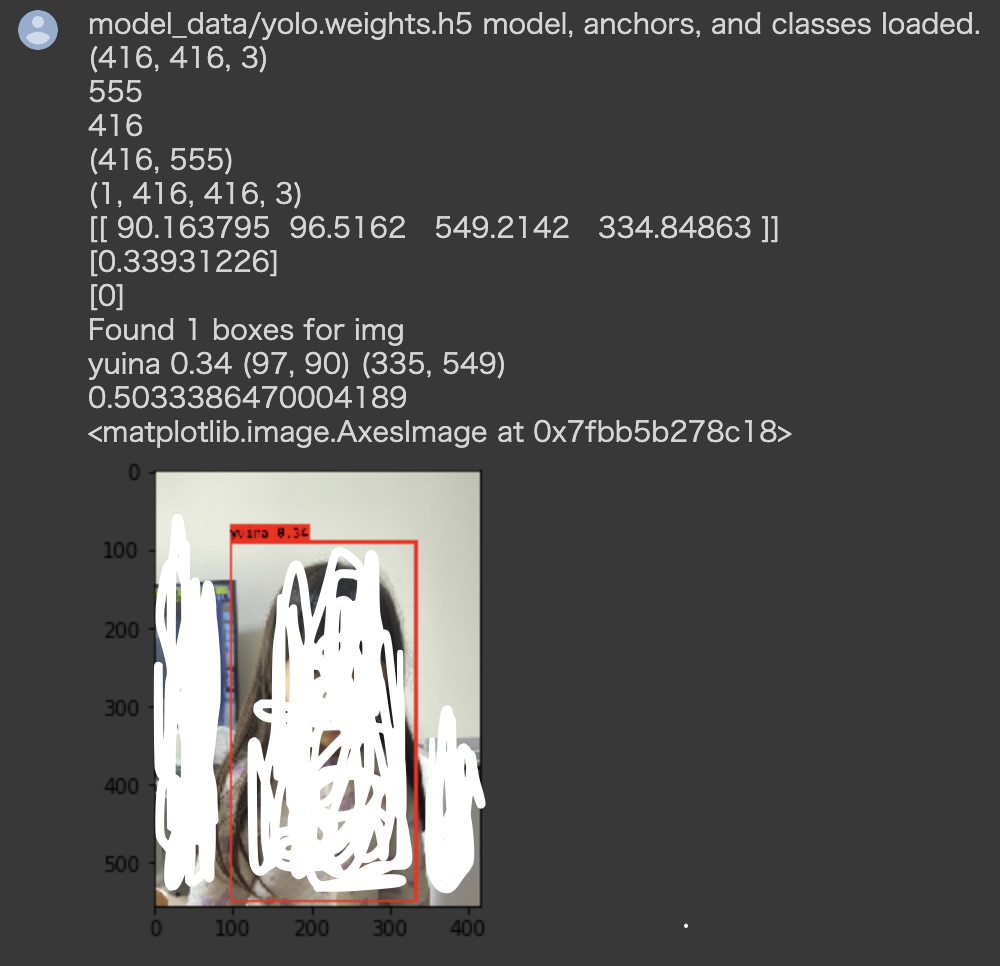
#検出の実行!!!!
import matplotlib.pyplot as plt
%matplotlib inline
from yolo2 import YOLO
from PIL import Image
yolo = YOLO()
#検出画像ファイル名にすること。
image = Image.open('yuina/yuina77.jpg')
r_image = yolo.detect_image(image)
plt.imshow(r_image)
↑を実行し、いい感じに検出ができると、ラベル付きの枠がでます。